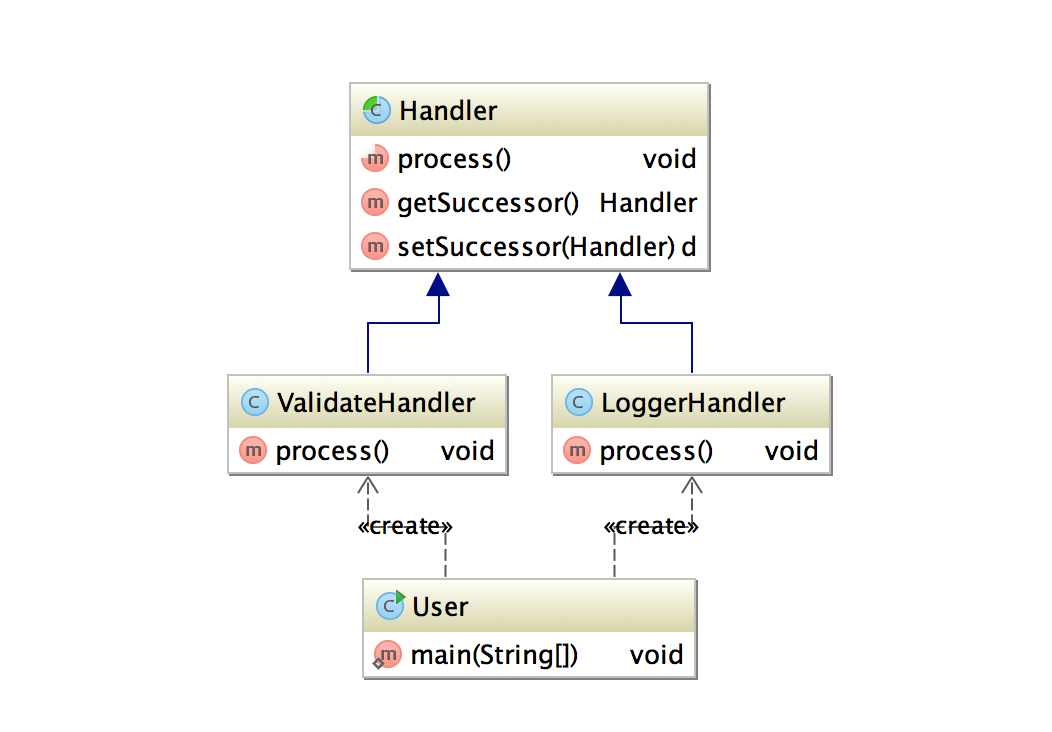
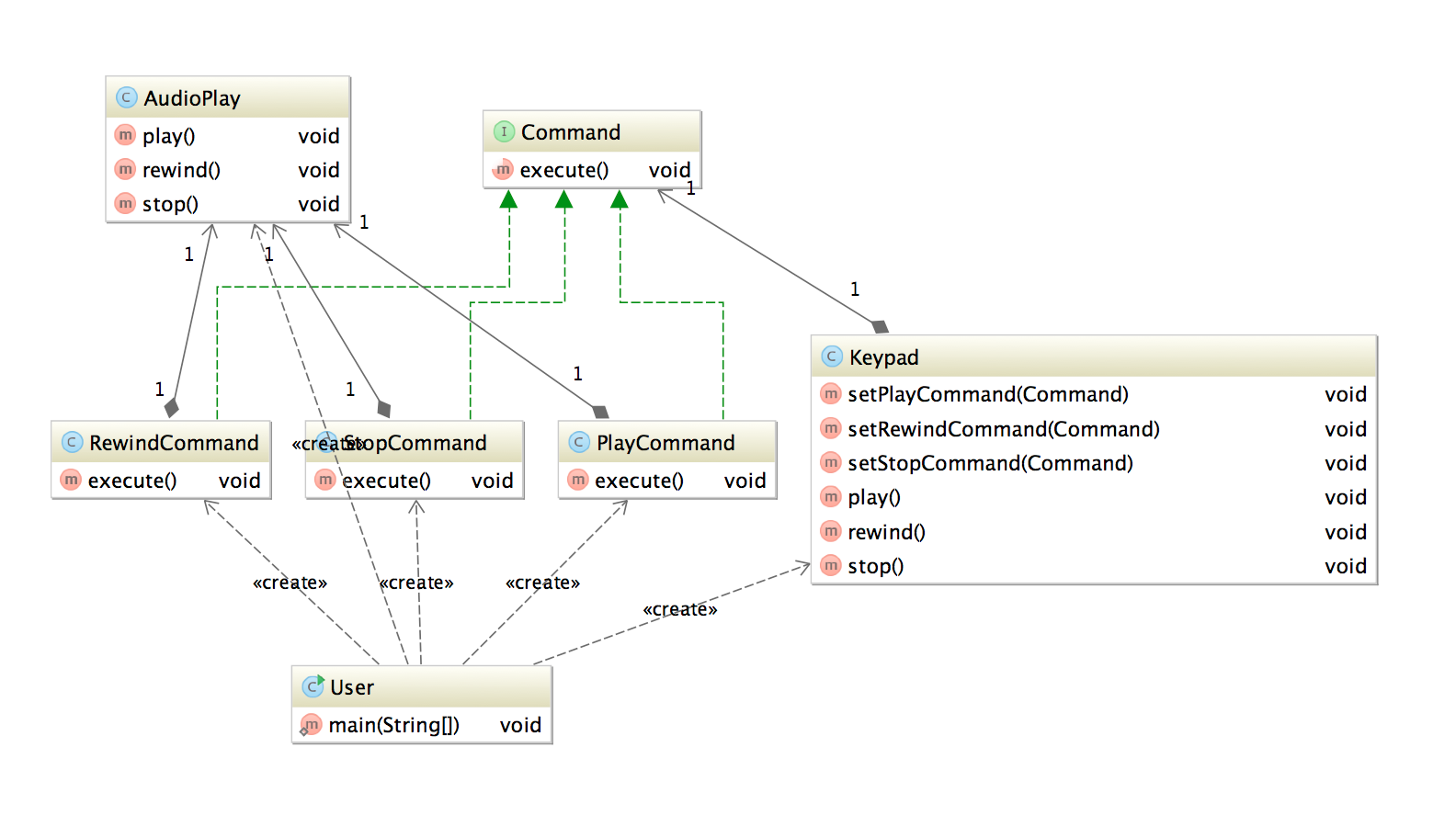
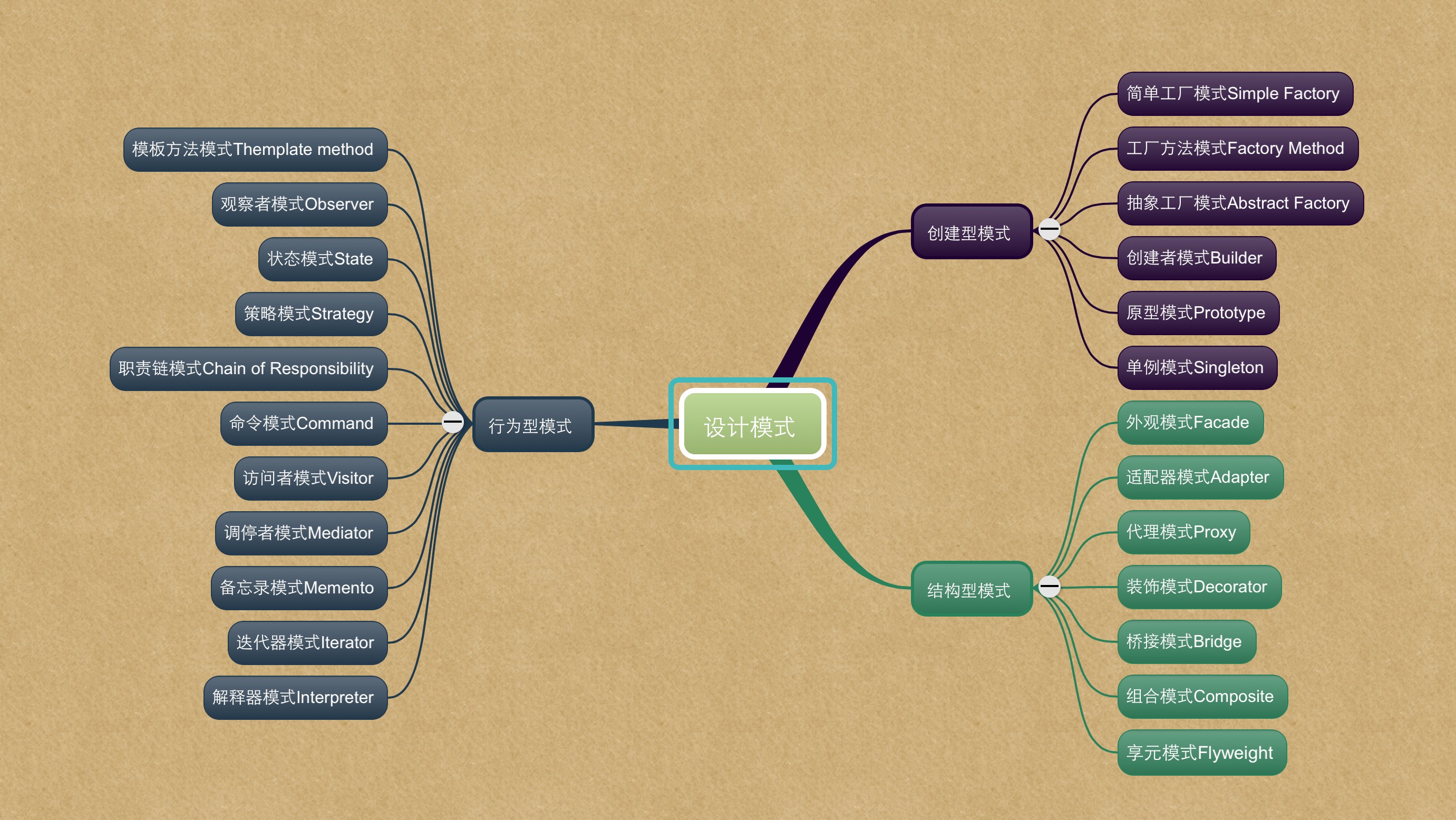
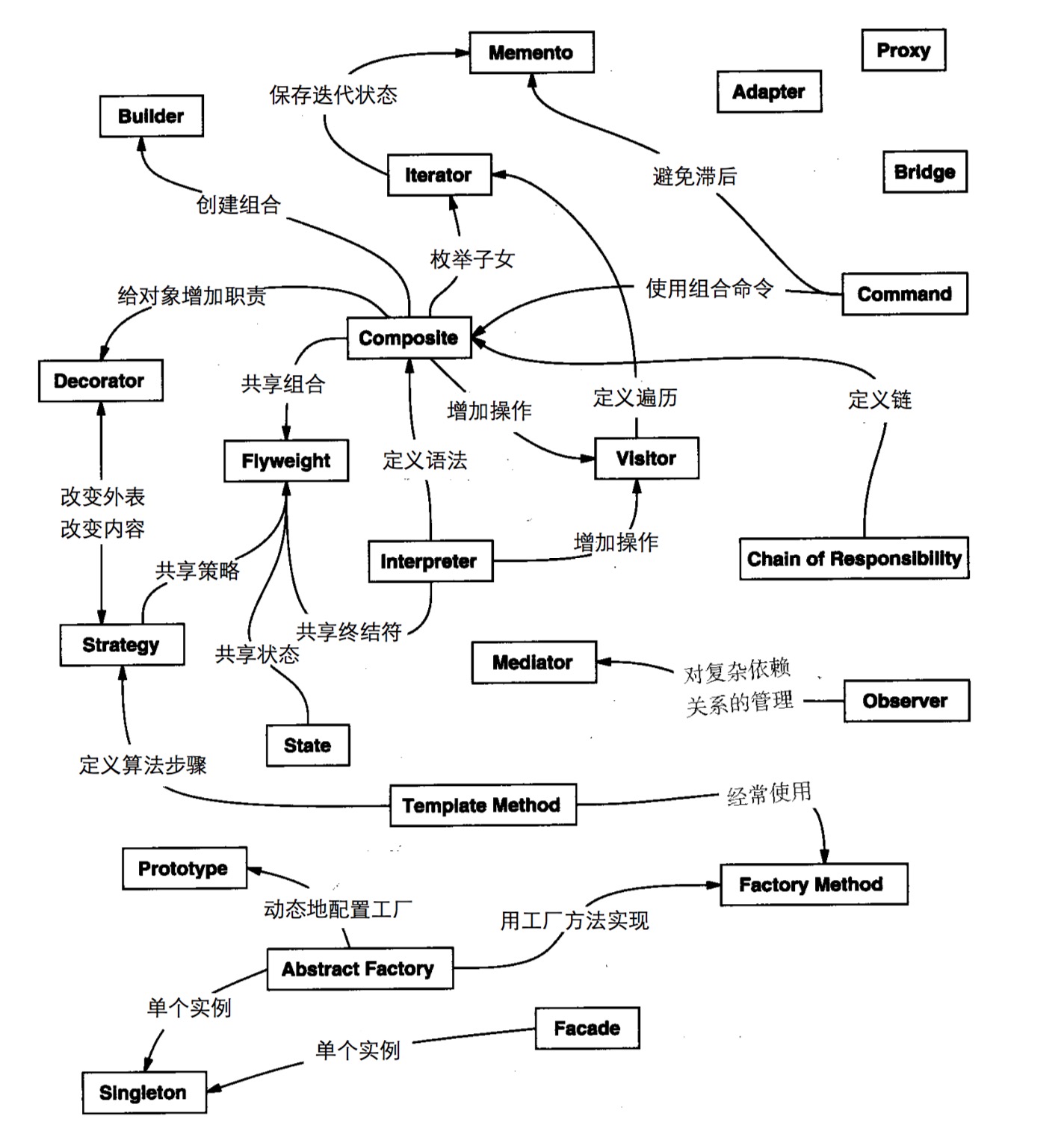
package java.util.concurrent;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.*;
public class ThreadPoolExecutor extends AbstractExecutorService {
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
private static boolean isRunning(int c) {
return c < SHUTDOWN;
}
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}
private boolean compareAndDecrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect - 1);
}
private void decrementWorkerCount() {
do {} while (! compareAndDecrementWorkerCount(ctl.get()));
}
private final BlockingQueue<Runnable> workQueue;
private final ReentrantLock mainLock = new ReentrantLock();
private final HashSet<Worker> workers = new HashSet<Worker>();
private final Condition termination = mainLock.newCondition();
private int largestPoolSize;
private long completedTaskCount;
private volatile ThreadFactory threadFactory;
private volatile RejectedExecutionHandler handler;
private volatile long keepAliveTime;
private volatile boolean allowCoreThreadTimeOut;
private volatile int corePoolSize;
private volatile int maximumPoolSize;
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
private static final RuntimePermission shutdownPerm =
new RuntimePermission("modifyThread");
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
private static final long serialVersionUID = 6138294804551838833L;
final Thread thread;
Runnable firstTask;
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1);
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
private void advanceRunState(int targetState) {
for (;;) {
int c = ctl.get();
if (runStateAtLeast(c, targetState) ||
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))
break;
}
}
final void tryTerminate() {
for (;;) {
int c = ctl.get();
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
if (workerCountOf(c) != 0) {
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated();
} finally {
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
}
}
private void checkShutdownAccess() {
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkPermission(shutdownPerm);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers)
security.checkAccess(w.thread);
} finally {
mainLock.unlock();
}
}
}
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers)
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
private static final boolean ONLY_ONE = true;
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
void onShutdown() {
}
final boolean isRunningOrShutdown(boolean shutdownOK) {
int rs = runStateOf(ctl.get());
return rs == RUNNING || (rs == SHUTDOWN && shutdownOK);
}
private List<Runnable> drainQueue() {
BlockingQueue<Runnable> q = workQueue;
ArrayList<Runnable> taskList = new ArrayList<Runnable>();
q.drainTo(taskList);
if (!q.isEmpty()) {
for (Runnable r : q.toArray(new Runnable[0])) {
if (q.remove(r))
taskList.add(r);
}
}
return taskList;
}
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get();
if (runStateOf(c) != rs)
continue retry;
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (w != null)
workers.remove(w);
decrementWorkerCount();
tryTerminate();
} finally {
mainLock.unlock();
}
}
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly)
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return;
}
addWorker(null, false);
}
}
private Runnable getTask() {
boolean timedOut = false;
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock();
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN);
interruptIdleWorkers();
onShutdown();
} finally {
mainLock.unlock();
}
tryTerminate();
}
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
public boolean isShutdown() {
return ! isRunning(ctl.get());
}
public boolean isTerminating() {
int c = ctl.get();
return ! isRunning(c) && runStateLessThan(c, TERMINATED);
}
public boolean isTerminated() {
return runStateAtLeast(ctl.get(), TERMINATED);
}
public boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (;;) {
if (runStateAtLeast(ctl.get(), TERMINATED))
return true;
if (nanos <= 0)
return false;
nanos = termination.awaitNanos(nanos);
}
} finally {
mainLock.unlock();
}
}
protected void finalize() {
shutdown();
}
public void setThreadFactory(ThreadFactory threadFactory) {
if (threadFactory == null)
throw new NullPointerException();
this.threadFactory = threadFactory;
}
public ThreadFactory getThreadFactory() {
return threadFactory;
}
public void setRejectedExecutionHandler(RejectedExecutionHandler handler) {
if (handler == null)
throw new NullPointerException();
this.handler = handler;
}
public RejectedExecutionHandler getRejectedExecutionHandler() {
return handler;
}
public void setCorePoolSize(int corePoolSize) {
if (corePoolSize < 0)
throw new IllegalArgumentException();
int delta = corePoolSize - this.corePoolSize;
this.corePoolSize = corePoolSize;
if (workerCountOf(ctl.get()) > corePoolSize)
interruptIdleWorkers();
else if (delta > 0) {
int k = Math.min(delta, workQueue.size());
while (k-- > 0 && addWorker(null, true)) {
if (workQueue.isEmpty())
break;
}
}
}
public int getCorePoolSize() {
return corePoolSize;
}
public boolean prestartCoreThread() {
return workerCountOf(ctl.get()) < corePoolSize &&
addWorker(null, true);
}
void ensurePrestart() {
int wc = workerCountOf(ctl.get());
if (wc < corePoolSize)
addWorker(null, true);
else if (wc == 0)
addWorker(null, false);
}
public int prestartAllCoreThreads() {
int n = 0;
while (addWorker(null, true))
++n;
return n;
}
public boolean allowsCoreThreadTimeOut() {
return allowCoreThreadTimeOut;
}
public void allowCoreThreadTimeOut(boolean value) {
if (value && keepAliveTime <= 0)
throw new IllegalArgumentException("Core threads must have nonzero keep alive times");
if (value != allowCoreThreadTimeOut) {
allowCoreThreadTimeOut = value;
if (value)
interruptIdleWorkers();
}
}
public void setMaximumPoolSize(int maximumPoolSize) {
if (maximumPoolSize <= 0 || maximumPoolSize < corePoolSize)
throw new IllegalArgumentException();
this.maximumPoolSize = maximumPoolSize;
if (workerCountOf(ctl.get()) > maximumPoolSize)
interruptIdleWorkers();
}
public int getMaximumPoolSize() {
return maximumPoolSize;
}
public void setKeepAliveTime(long time, TimeUnit unit) {
if (time < 0)
throw new IllegalArgumentException();
if (time == 0 && allowsCoreThreadTimeOut())
throw new IllegalArgumentException("Core threads must have nonzero keep alive times");
long keepAliveTime = unit.toNanos(time);
long delta = keepAliveTime - this.keepAliveTime;
this.keepAliveTime = keepAliveTime;
if (delta < 0)
interruptIdleWorkers();
}
public long getKeepAliveTime(TimeUnit unit) {
return unit.convert(keepAliveTime, TimeUnit.NANOSECONDS);
}
public BlockingQueue<Runnable> getQueue() {
return workQueue;
}
public boolean remove(Runnable task) {
boolean removed = workQueue.remove(task);
tryTerminate();
return removed;
}
public void purge() {
final BlockingQueue<Runnable> q = workQueue;
try {
Iterator<Runnable> it = q.iterator();
while (it.hasNext()) {
Runnable r = it.next();
if (r instanceof Future<?> && ((Future<?>)r).isCancelled())
it.remove();
}
} catch (ConcurrentModificationException fallThrough) {
for (Object r : q.toArray())
if (r instanceof Future<?> && ((Future<?>)r).isCancelled())
q.remove(r);
}
tryTerminate();
}
public int getPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
return runStateAtLeast(ctl.get(), TIDYING) ? 0
: workers.size();
} finally {
mainLock.unlock();
}
}
public int getActiveCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int n = 0;
for (Worker w : workers)
if (w.isLocked())
++n;
return n;
} finally {
mainLock.unlock();
}
}
public int getLargestPoolSize() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
return largestPoolSize;
} finally {
mainLock.unlock();
}
}
public long getTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
long n = completedTaskCount;
for (Worker w : workers) {
n += w.completedTasks;
if (w.isLocked())
++n;
}
return n + workQueue.size();
} finally {
mainLock.unlock();
}
}
public long getCompletedTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
long n = completedTaskCount;
for (Worker w : workers)
n += w.completedTasks;
return n;
} finally {
mainLock.unlock();
}
}
public String toString() {
long ncompleted;
int nworkers, nactive;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
ncompleted = completedTaskCount;
nactive = 0;
nworkers = workers.size();
for (Worker w : workers) {
ncompleted += w.completedTasks;
if (w.isLocked())
++nactive;
}
} finally {
mainLock.unlock();
}
int c = ctl.get();
String rs = (runStateLessThan(c, SHUTDOWN) ? "Running" :
(runStateAtLeast(c, TERMINATED) ? "Terminated" :
"Shutting down"));
return super.toString() +
"[" + rs +
", pool size = " + nworkers +
", active threads = " + nactive +
", queued tasks = " + workQueue.size() +
", completed tasks = " + ncompleted +
"]";
}
protected void beforeExecute(Thread t, Runnable r) { }
protected void afterExecute(Runnable r, Throwable t) { }
protected void terminated() { }
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
}
|