#错误描述
我们将文件缓存到redis,但是在线上出现了一个问题,就是A企业群中发的文件,在B企业群中看文件时却看到了A企业群中的图片。
#经排查,结果如下:
##案例代码如下:
import com.google.common.collect.Lists;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.*;
/**
* Created by Aaron on 15/11/12.
*/
public class FileRedisFactory {
private static Logger log = LoggerFactory.getLogger(FileRedisFactory.class);
public ThreadPoolExecutor threadPoolExecutor;
// 格式为 : 127.0.0.1:6379#0;127.0.0.2:6379#1 IP:PORT#index
private String hosts;
private String password;
private int size;
private List<JedisPool> pools=Lists.newArrayList();//连接池
public FileRedisFactory(String hosts, String password) {
this.hosts = hosts;
this.password = password;
this.init(hosts, password);
}
public FileRedisFactory(String hosts) {
this.hosts = hosts;
this.init(hosts, null);
}
private synchronized void init(String hosts, String password) {
if (StringUtils.isNotEmpty(hosts)) {
String[] hostsArray = hosts.split(";");
List<String> hostList = Arrays.asList(hostsArray);
Collections.sort(hostList);
System.out.println(hostList);
for (String host : hostList) {
try {
String[] uriDb=host.split("#");
String[] host_port = uriDb[0].split(":");
String ip = host_port[0];
String port = host_port[1];
int index=uriDb.length>0?Integer.valueOf(uriDb[1]):0;
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
poolConfig.setMaxTotal(16);
poolConfig.setMaxIdle(16);
if (StringUtils.isNotEmpty(password)) {
pools.add(new JedisPool(poolConfig, ip, Integer.valueOf(port), 2000, password, index));
} else {
pools.add(new JedisPool(poolConfig, ip, Integer.valueOf(port), 2000, null, index));
}
} catch (Exception e) {
pools = Lists.newArrayList();
e.printStackTrace();
log.error("[ShardedRedisFactory] [initByShard] [error] [hosts:" + hosts + "] [password:" + password + "]", e);
}
}
size = pools.size();
}
this.threadPoolExecutor = new ThreadPoolExecutor(10,20,3, TimeUnit.MINUTES,new LinkedBlockingDeque<>(),new ThreadPoolExecutor.DiscardPolicy());
// 构造池
log.info("[ShardedRedisFactory] [initByShard] [success] [hosts:{}] [password:{}] [masterName:{}] [pool:{}]", hosts, password);
}
private JedisPool getJedisPool(int c) {
int index = c % size;
return pools.get(index);
}
private static int getIndexFromPath(String path) {
String first=path.split("\\.")[0];
return first.charAt(first.length() - 1);
}
/**
* @param filePath file path
* @return
*/
public byte[] get(String filePath) {
if (cacheIsAvailable()) return null;
JedisPool jedisPool = getJedisPool(getIndexFromPath(filePath));
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
return jedis.get(filePath.getBytes());
} catch (Exception e) {
log.error(e.getMessage());
return null;
} finally {
if (jedis != null)
jedisPool.returnResource(jedis);
}
}
public void asynSet(String filePath, byte[] datas){
if (cacheIsAvailable()) return;
threadPoolExecutor.execute(()->{
JedisPool jedisPool = getJedisPool(getIndexFromPath(filePath));
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.set(filePath.getBytes(), datas);
} catch (Exception e) {
log.error(e.getMessage());
} finally {
if (jedis != null)
jedisPool.returnResource(jedis);
}
});
}
private boolean cacheIsAvailable() {
if(pools.size()==0){
return true;
}
return false;
}
}
##测试代码如下
public static void main(String[] args) {
FileRedisFactory fileRedisFactory = new FileRedisFactory("172.31.xxx.xxx:6379#0;172.31.xx.xxx:6379#1;172.31.xxx.xxx:6379#2;172.31.xxx.xxx:6379#3");
System.out.println(fileRedisFactory);
Map<String,String> map=new HashMap<>();
for(int i=0;i<20;i++){
map.put(""+i,""+i);
}
for (int j = 0; j <50 ; j++) {
Thread thread=new Thread(){
@Override
public void run() {
while(true){
Set<String> s=map.keySet();
s.forEach(i->{
fileRedisFactory.set(i + "", (i + "").getBytes());
});
}
}
};
thread.start();
}
for (int k = 0; k <50 ; k++) {
Thread thread=new Thread(){
@Override
public void run() {
while(true){
Set<String> s=map.keySet();
s.forEach(i->{
byte[] first=fileRedisFactory.get(i+"");
if(first==null){
System.out.println(i+""+first);
return;
}
try{
String temp=(new String(first));
if(!temp.equals(i+"")){
System.out.println(i+"======"+temp);
System.exit(-1);
}}catch(Exception e){
e.printStackTrace();
}
});
}
}
};
thread.start();
}
}
若你和连接到redis服务器之间的网络不是很稳定
在运行时,我们会发现,有奇怪的现像出现:
1======2
3======8
这时,我们就在对redis操作时,异常的地方修改成如下代码:
catch (Exception e) {
log.error(e.getMessage());
e.printStackTrace();
return null;
}
就会看到报TimeOut的Exception
我们将:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.6.2</version>
</dependency>
替换成:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.3</version>
</dependency>
这时我们去Google上查询的同时也看了一下新的代码,
我们原来用的:
jedisPool.returnResource(jedis);
已经变成了:
/**
* @deprecated starting from Jedis 3.0 this method won't exist. Resouce cleanup should be done
* using @see {@link redis.clients.jedis.Jedis#close()}
*/
@Deprecated
public void returnResource(final Jedis resource) {
if (resource != null) {
try {
resource.resetState();
returnResourceObject(resource);
} catch (Exception e) {
returnBrokenResource(resource);
throw new JedisException("Could not return the resource to the pool", e);
}
}
}
同时我们也查到了一个文章JedisPool异常Jedis链接处理
#修改后的代码:
import com.google.common.collect.Lists;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.pool2.impl.GenericObjectPoolConfig;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.*;
/**
* Created by Aaron on 15/11/12.
*/
public class FileRedisFactory {
private static Logger log = LoggerFactory.getLogger(FileRedisFactory.class);
public ThreadPoolExecutor threadPoolExecutor;
// 格式为 : 127.0.0.1:6379#0;127.0.0.2:6379#1 IP:PORT#index
private String hosts;
private String password;
private int size;
private List<JedisPool> pools=Lists.newArrayList();//连接池
public FileRedisFactory(String hosts, String password) {
this.hosts = hosts;
this.password = password;
this.init(hosts, password);
}
public FileRedisFactory(String hosts) {
this.hosts = hosts;
this.init(hosts, null);
}
private synchronized void init(String hosts, String password) {
if (StringUtils.isNotEmpty(hosts)) {
String[] hostsArray = hosts.split(";");
List<String> hostList = Arrays.asList(hostsArray);
Collections.sort(hostList);
System.out.println(hostList);
for (String host : hostList) {
try {
String[] uriDb=host.split("#");
String[] host_port = uriDb[0].split(":");
String ip = host_port[0];
String port = host_port[1];
int index=uriDb.length>0?Integer.valueOf(uriDb[1]):0;
GenericObjectPoolConfig poolConfig = new GenericObjectPoolConfig();
poolConfig.setMaxTotal(16);
poolConfig.setMaxIdle(16);
if (StringUtils.isNotEmpty(password)) {
pools.add(new JedisPool(poolConfig, ip, Integer.valueOf(port), 2000, password, index));
} else {
pools.add(new JedisPool(poolConfig, ip, Integer.valueOf(port), 2000, null, index));
}
} catch (Exception e) {
pools = Lists.newArrayList();
log.error("[ShardedRedisFactory] [initByShard] [error] [hosts:" + hosts + "] [password:" + password + "]", e);
}
}
size = pools.size();
}
this.threadPoolExecutor = new ThreadPoolExecutor(10,20,3, TimeUnit.MINUTES,new LinkedBlockingDeque<>(50),new ThreadPoolExecutor.DiscardPolicy());
// 构造池
log.info("[ShardedRedisFactory] [initByShard] [success] [hosts:{}] [password:{}] [masterName:{}] [pool:{}]", hosts, password);
}
private JedisPool getJedisPool(int c) {
int index = c % size;
return pools.get(index);
}
private static int getIndexFromPath(String path) {
String first=path.split("\\.")[0];
return first.charAt(first.length() - 1);
}
/**
* @param filePath file path
* @return
*/
public byte[] get(String filePath) {
if (cacheIsAvailable()) return null;
JedisPool jedisPool = getJedisPool(getIndexFromPath(filePath));
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
return jedis.get(filePath.getBytes());
} catch (Exception e) {
log.error(e.getMessage());
return null;
} finally {
if (jedis != null)
jedis.close();
}
}
public String set(String filePath, byte[] datas) {
if (cacheIsAvailable()) return null;
JedisPool jedisPool = getJedisPool(getIndexFromPath(filePath));
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
return jedis.set(filePath.getBytes(), datas);
} catch (Exception e) {
log.error(e.getMessage());
return null;
} finally {
if (jedis != null)
jedis.close();
}
}
public void asynSet(String filePath, byte[] datas,long expx){
if (cacheIsAvailable()) return;
threadPoolExecutor.execute(()->{
JedisPool jedisPool = getJedisPool(getIndexFromPath(filePath));
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.set(filePath.getBytes(), datas,"NX".getBytes(),"EX".getBytes(),expx);
} catch (Exception e) {
log.error(e.getMessage());
} finally {
if (jedis != null)
jedis.close();
}
});
}
private boolean cacheIsAvailable() {
if(pools.size()==0){
return true;
}
return false;
}
}
#总结:
- 在使用做新功能时,方便时要添加开关或合理的回滚方案,方便快速的回滚减少事故的影响
- 排查错误,一查到底
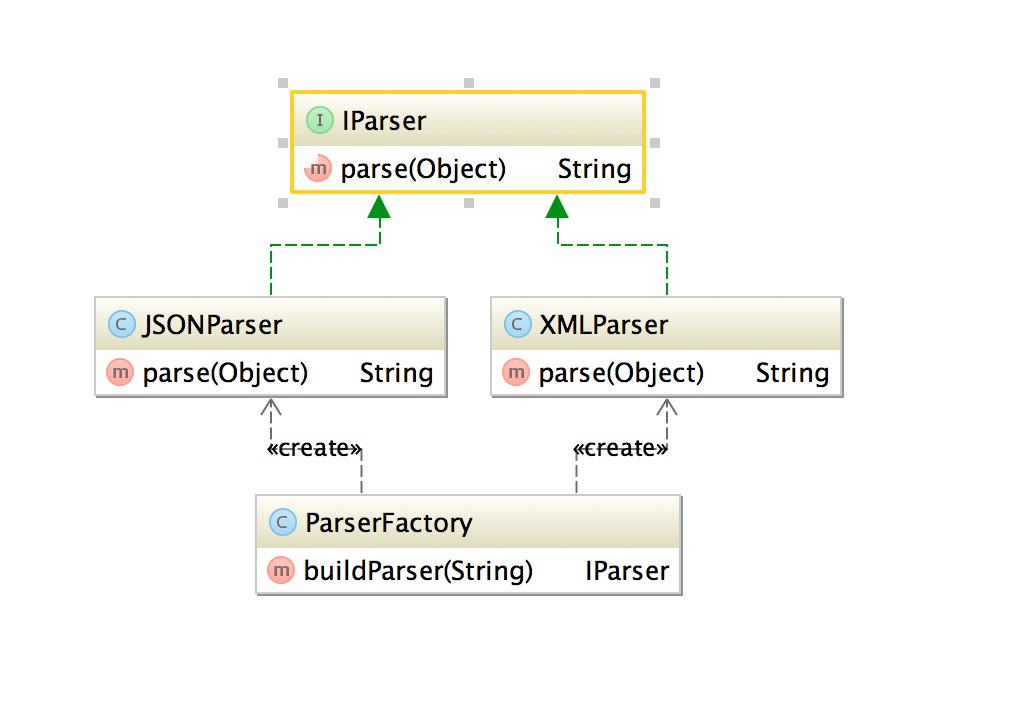 ``
``
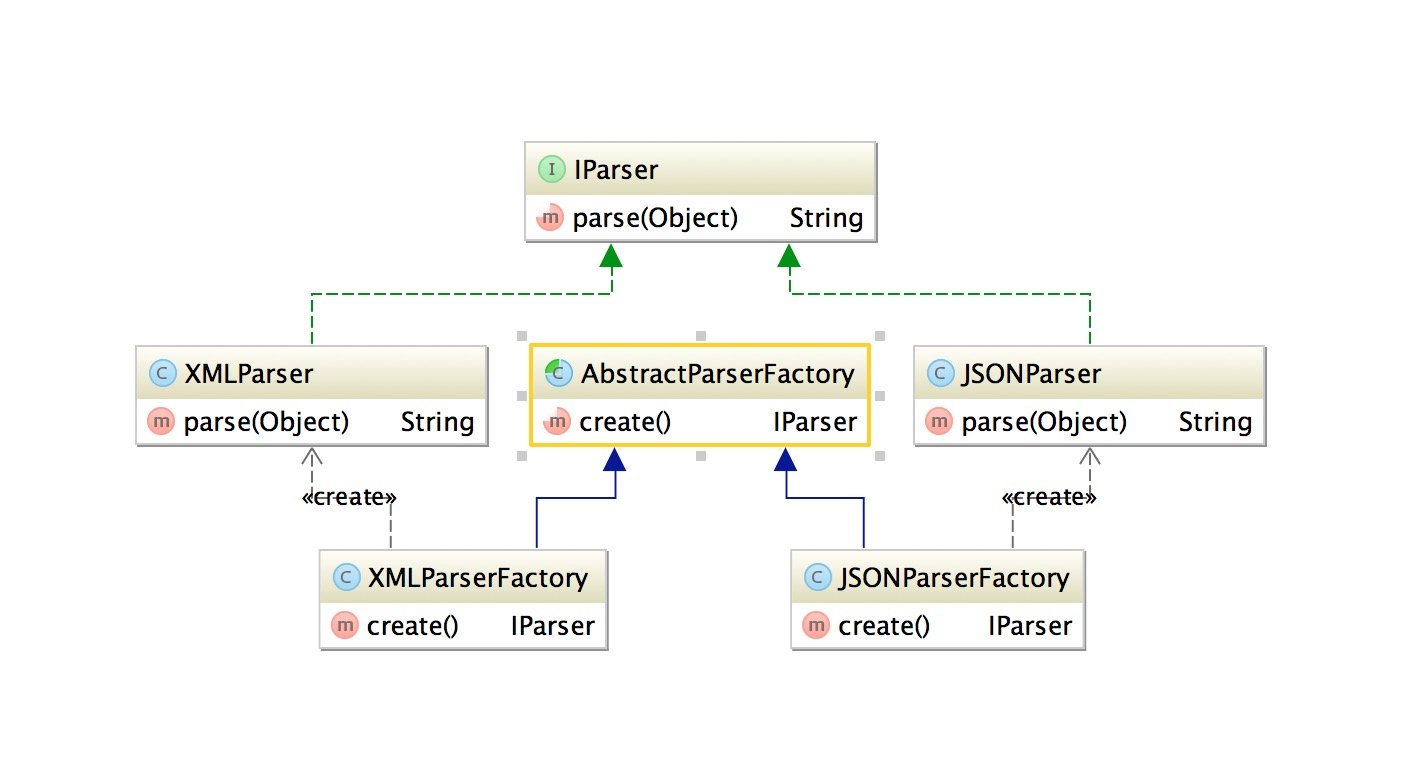 基于上面代码将ParserFactory工厂类用一个抽象工厂类和两个子工厂类进行代替
基于上面代码将ParserFactory工厂类用一个抽象工厂类和两个子工厂类进行代替
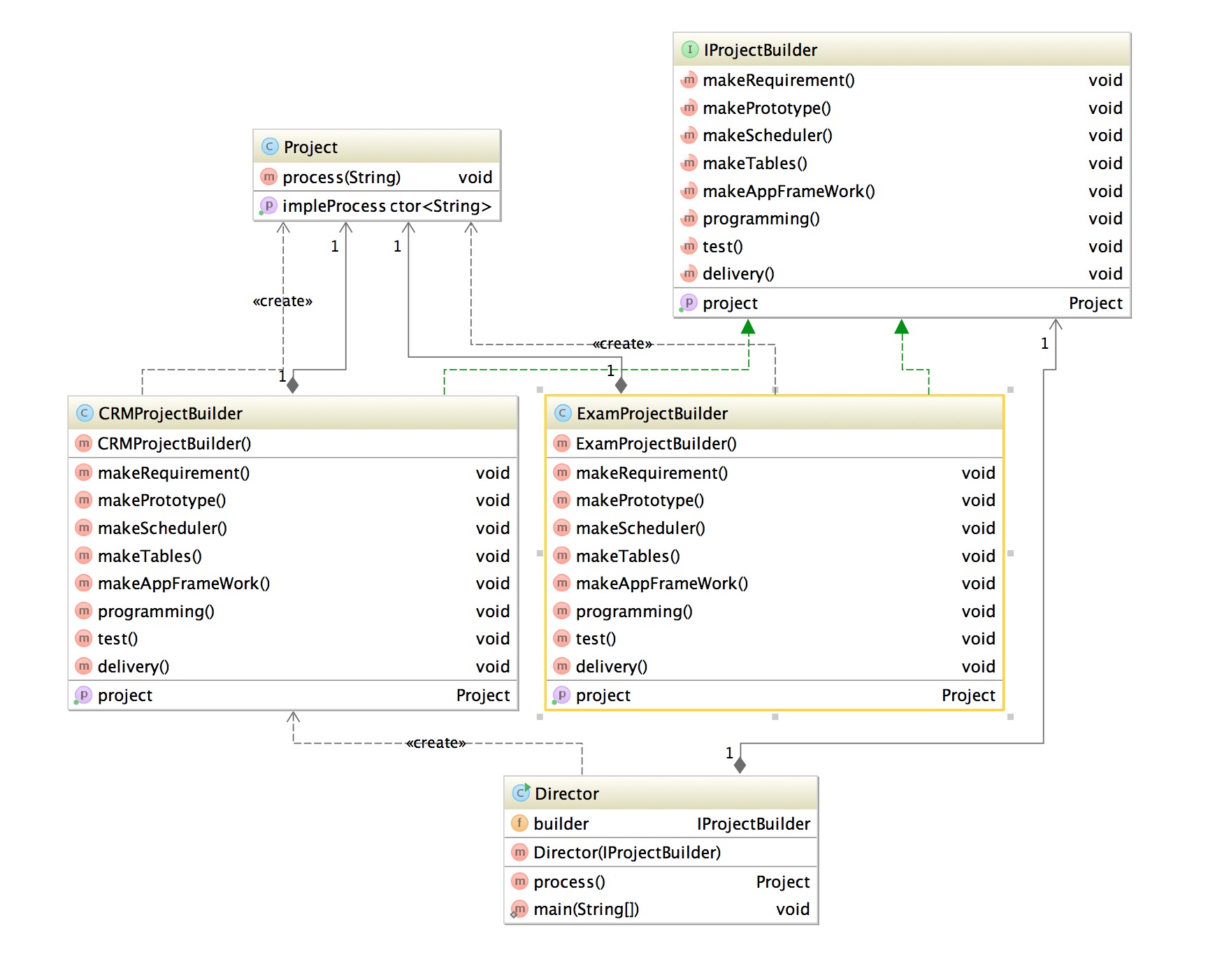 咱们这里以创建应用为例,这里我们创建两个应用,考试系统和CRM系统,创建过程是,需求->原型图->开发计划->表设计->架构设计->功能实现->测试->交付 大概是这样一个简单的过程,这里就会看到同样的构建过程得到不同的表示。
咱们这里以创建应用为例,这里我们创建两个应用,考试系统和CRM系统,创建过程是,需求->原型图->开发计划->表设计->架构设计->功能实现->测试->交付 大概是这样一个简单的过程,这里就会看到同样的构建过程得到不同的表示。